Building Assignments on Learn.co
This post originally appeared on the Flatiron School engineering blog.
The product and engineering team at Flatiron School recently released Assignments on Learn.co, a feature that allows admins of the platform to assign individual students tasks to do. Read on to learn more about the origin of this feature, the problems it solves, and what challenges (and wins!) the team faced.
When Flatiron School first introduced Code Challenges to the in-person software engineering immersive program in March of 2017, the workflow to deploy and grade those challenges was a very manual one for our instructors and technical coaching fellows.
Like much of our curriculum, code challenges are repositories on GitHub. Administering a challenge involves the following:
- Cloning down a templated curriculum repository from our learn-co-curriculum GitHub organization
- Removing the solution
- Renaming the repository for the cohort
- Creating a student-facing private repository on our learn-co-students GitHub organization
- Pushing up the code for the challenge to that repo
- Looking up each student’s GitHub username and adding them manually as collaborators to the repo to grant read access. (In some cases, adding the GitHub team to the repo also works)
When the challenge begins, instructors send out a link to the private repo to their class. Students fork the repository under their own GitHub accounts, write some code, and then submit a pull request to indicate they’re done. This process resembles the way that labs are delivered to and completed by students on Learn.co and the way that our signature lights work—only for Code Challenges, there is no test suite.
Once the challenge is over, the education team divvies up the submissions and grades each one by viewing the code diff, usually on GitHub itself, running the code, comparing the results to a rubric, and then logging feedback in a spreadsheet. They later copy and paste the feedback from a spreadsheet and email it to the student.
In total, the grading process takes an average of 6 hours per instructor, according to a recent survey of the education staff. Multiply that by 3 instructors per cohort and 4 cohorts taking a challenge each week and that time quickly adds up.
After interviewing our educators and shadowing this process, the product and engineering teams began work to operationalize and standardize the code challenge workflow. The result is the recently launched Assignments feature on Learn, which not only automates much of the code challenge deployment process and provides a new way for Flatiron School staff to give individual students one-off tasks, but also decreased the average grading time for a code challenge by 50 percent to 3 hours per instructor.
How It Works: An Overview
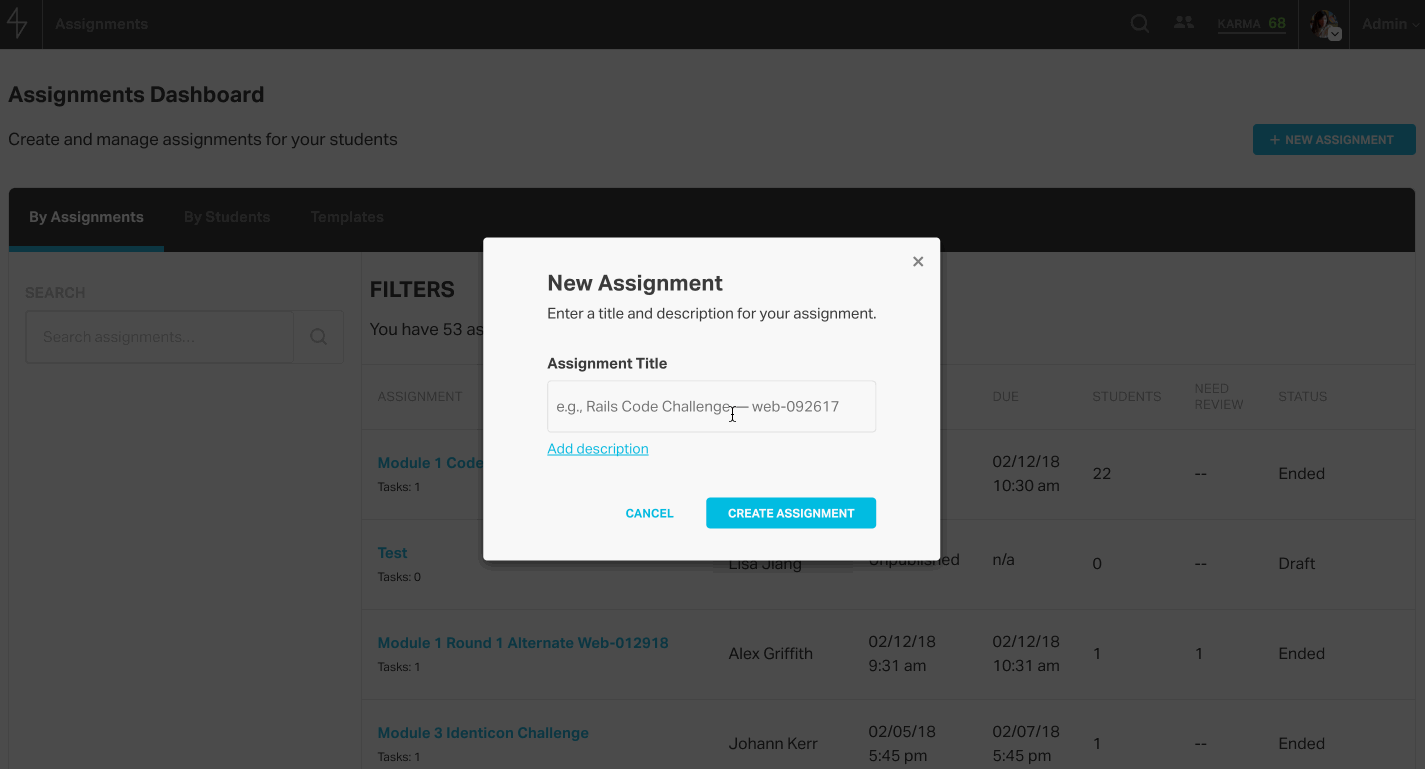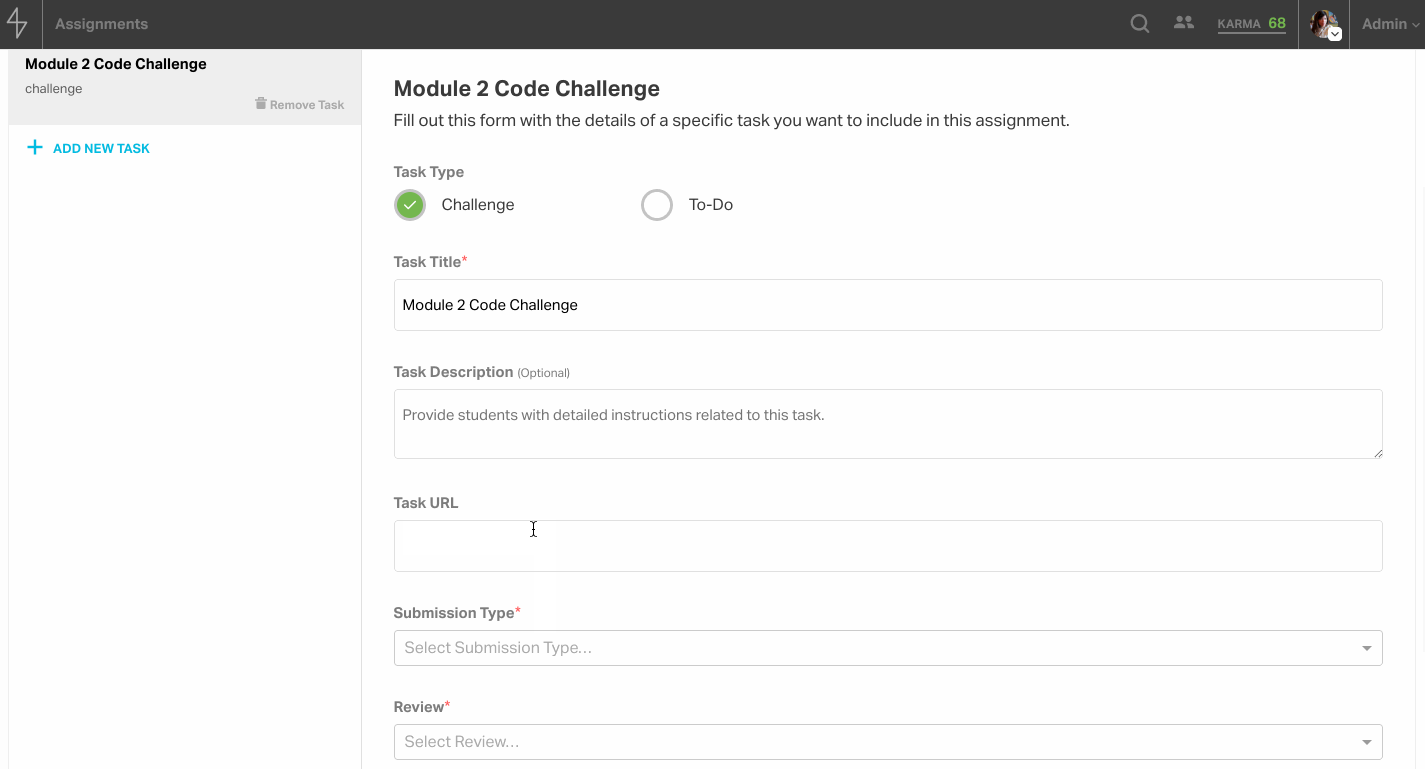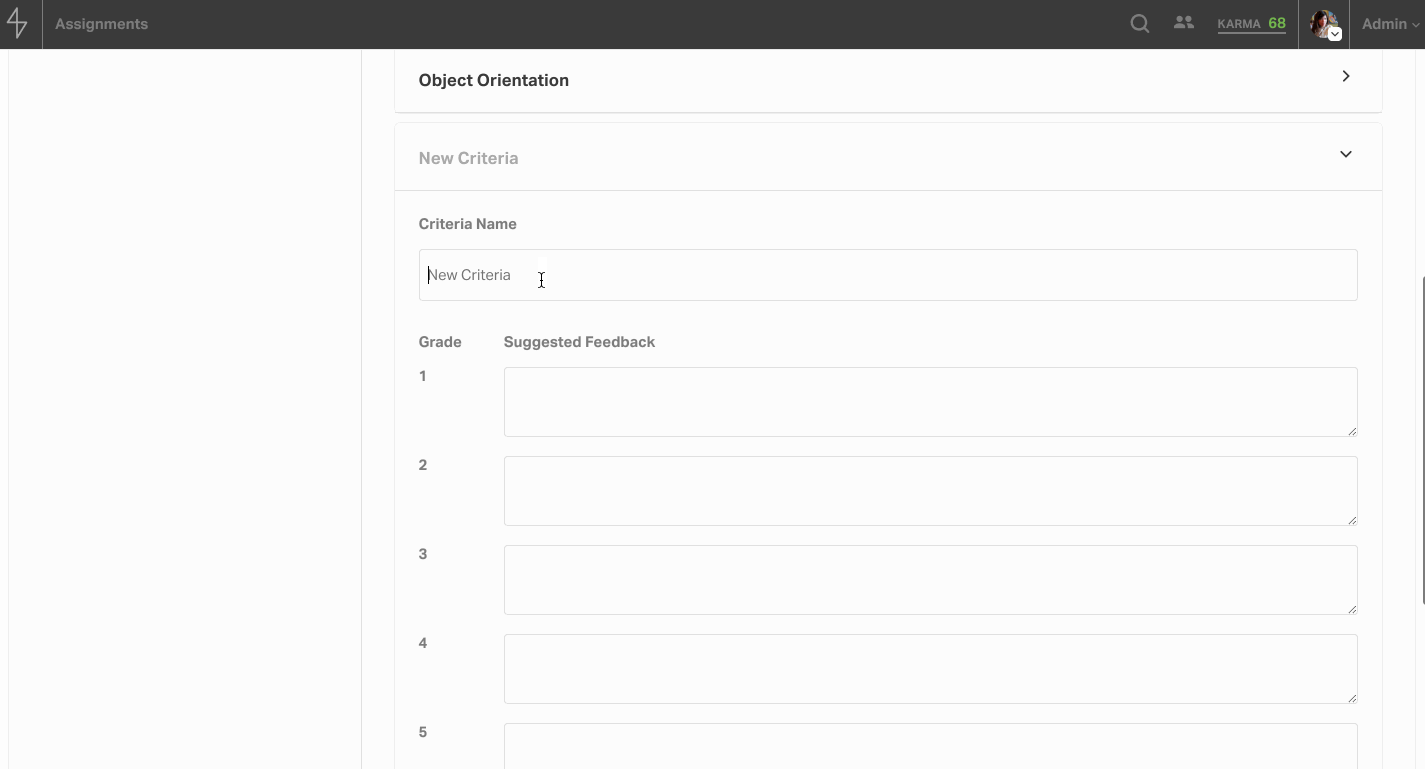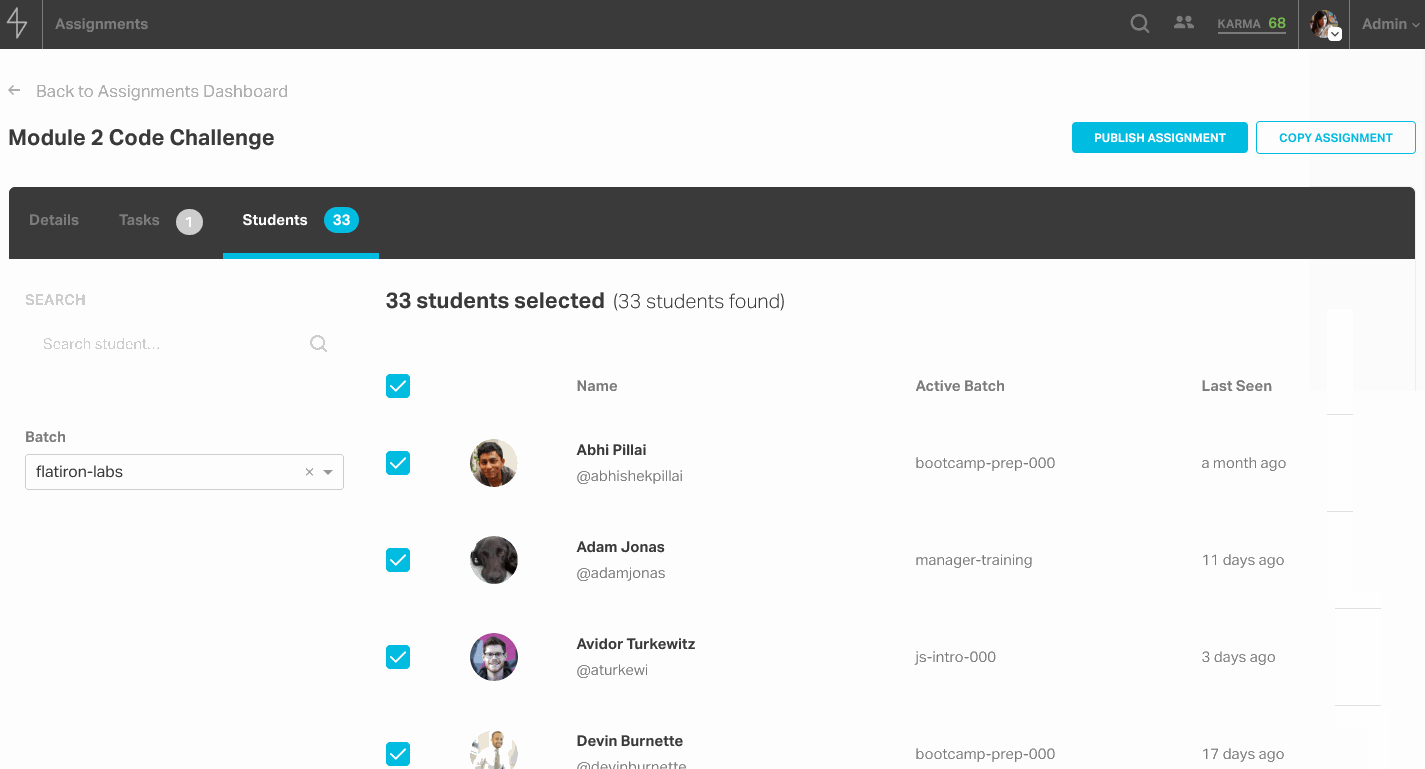
From the assignments dashboard, admins on Learn can see and search through all the existing assignments. They can also click into an assignment to view its details or edit it, or they can create a new assignment.
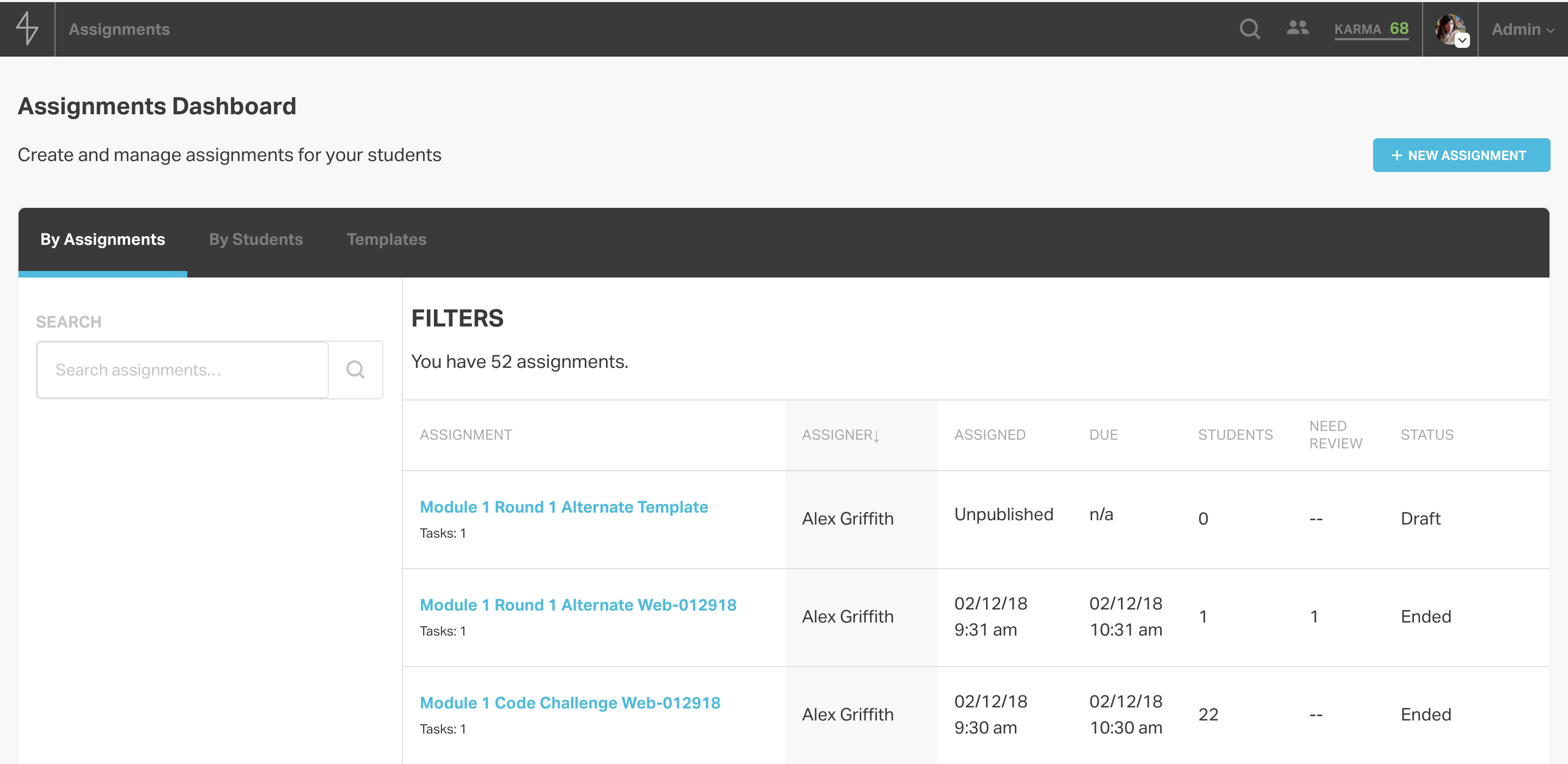
In the assignment editor, admins can modify the details of the assignment, set a duration, and add collaborators who can edit and grade the assignment.
The tasks tab allows admins to add one or more tasks to the assignment. Tasks can either be code challenges or generic to-dos. They also can have different submission types and can be gradable or confirmable.
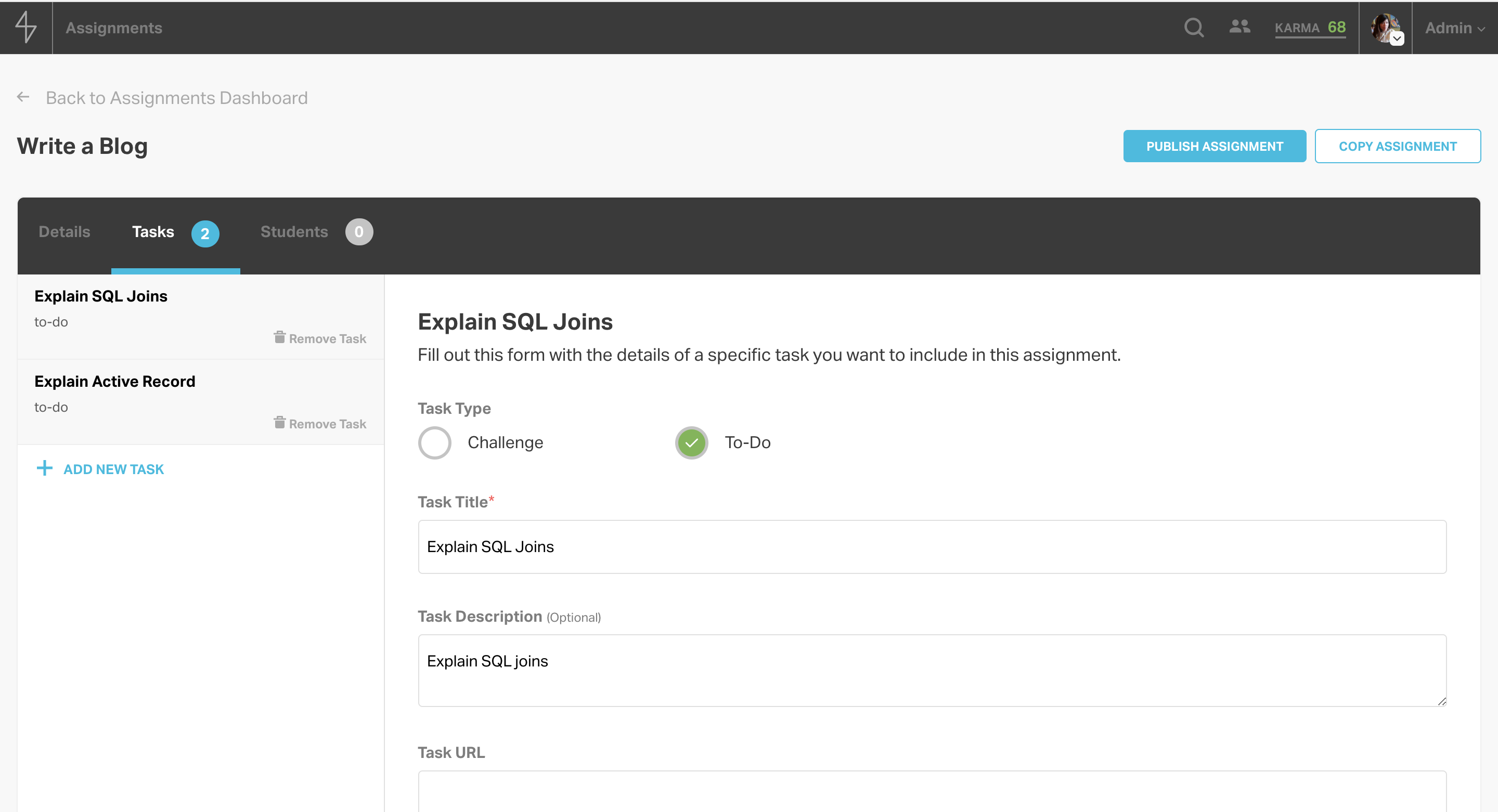
Graded tasks require a rubric, and this rubric consists of different grading criteria. For each criterion, the assignment’s creator can enter templated feedback for each score. On the final tab, admins can assign a group of students or just one student a task by searching by cohort or by student.
After an assignment is published, the assignment is no longer modifiable and instead displays a grading overview, which can be toggled to a master-detail view to facilitate faster grading. The grader view is especially noteworthy because when an admin grading the assignment selects a score, the student feedback text area populates with the templated feedback, so that the admin can build on top of boilerplate and add any details they see fit.
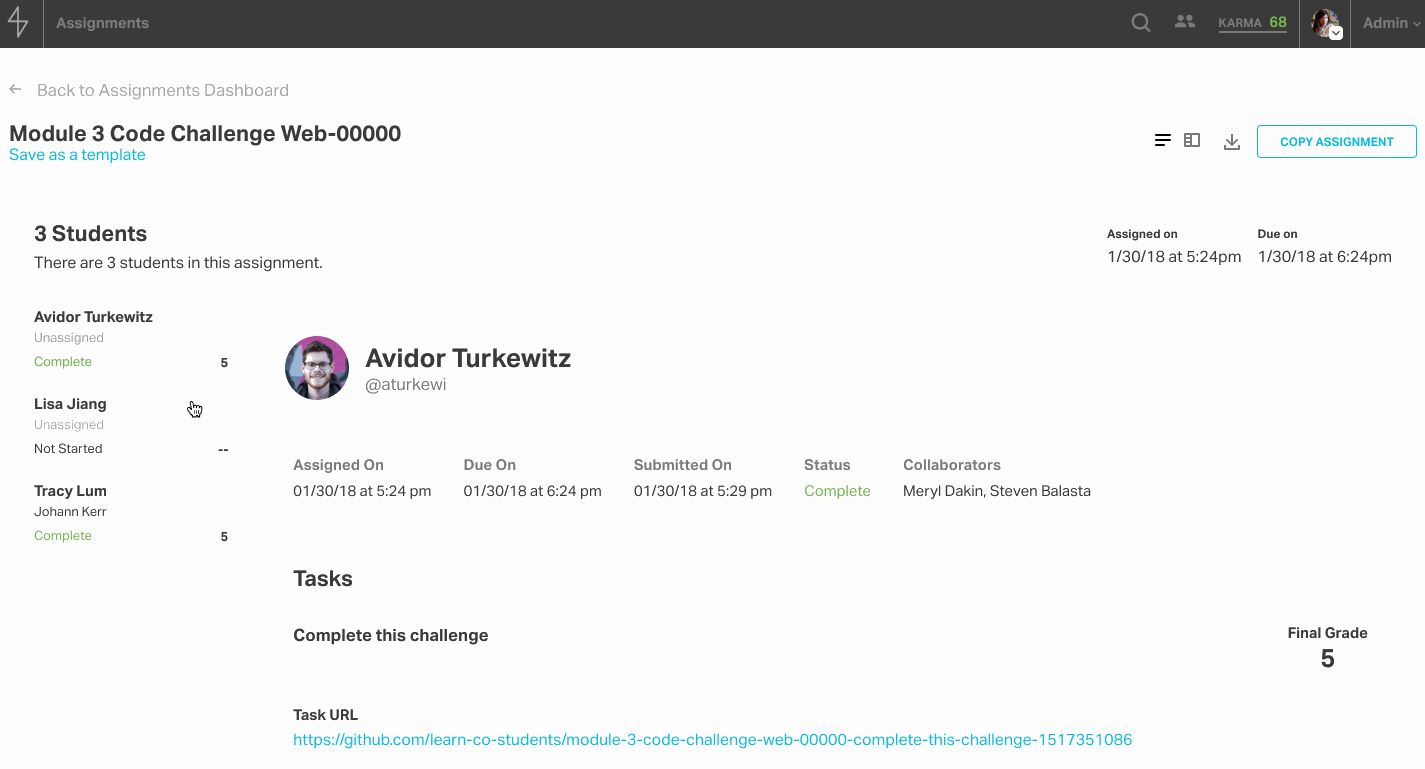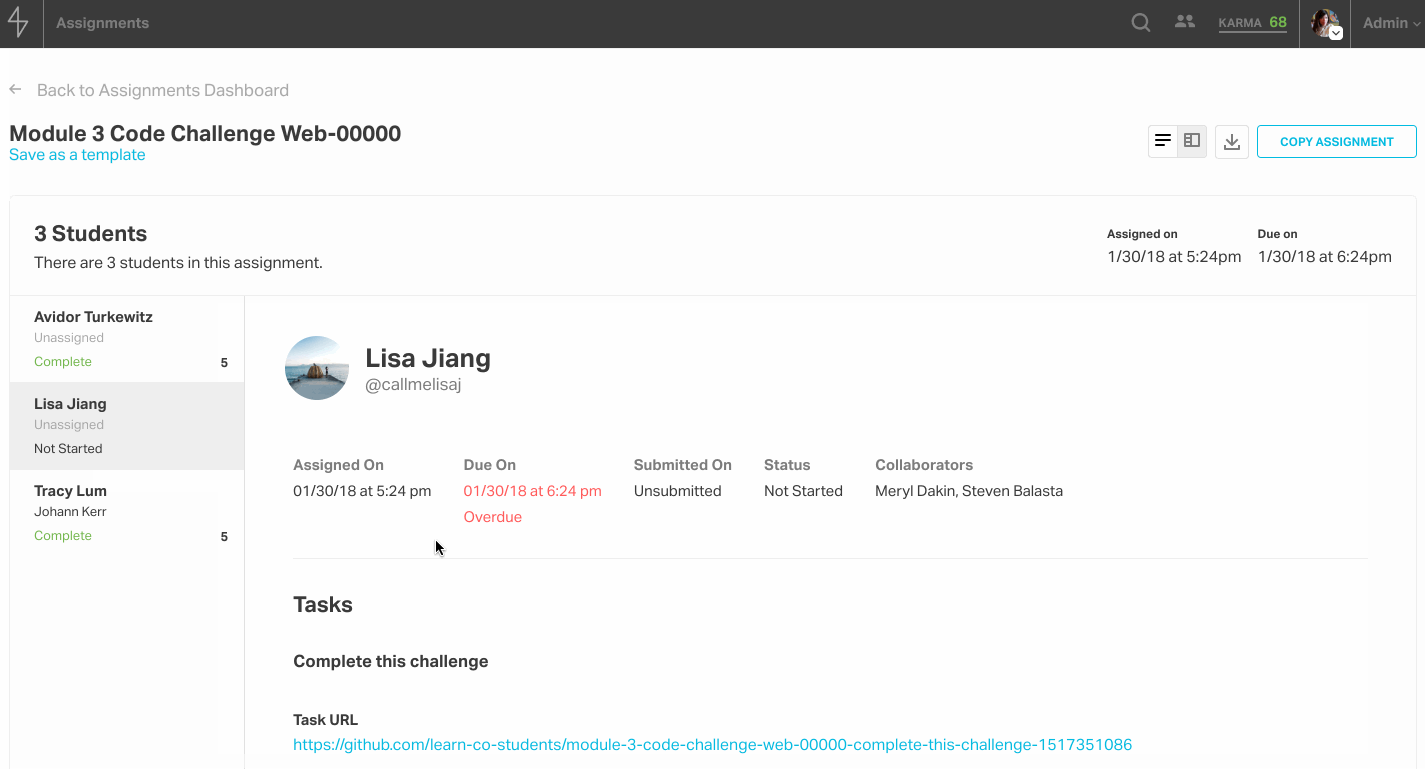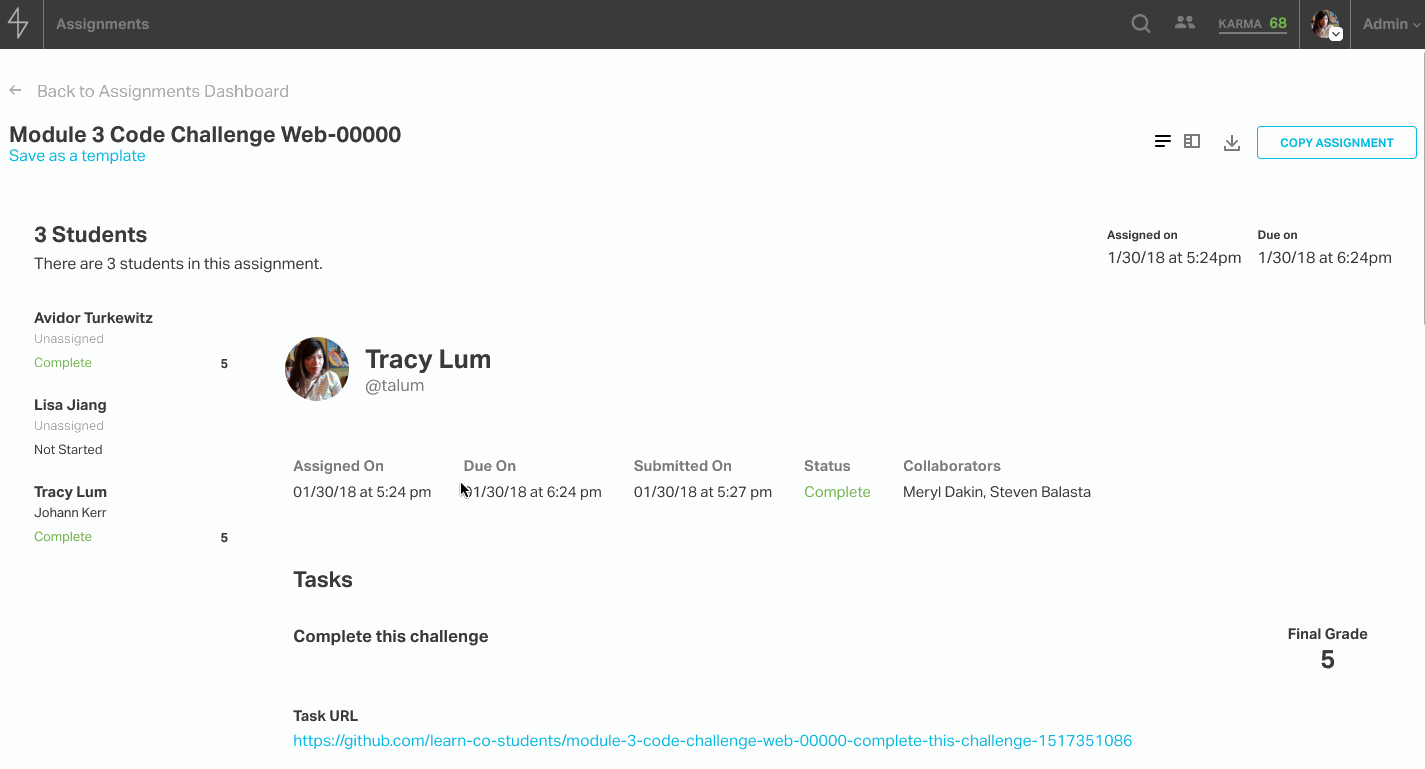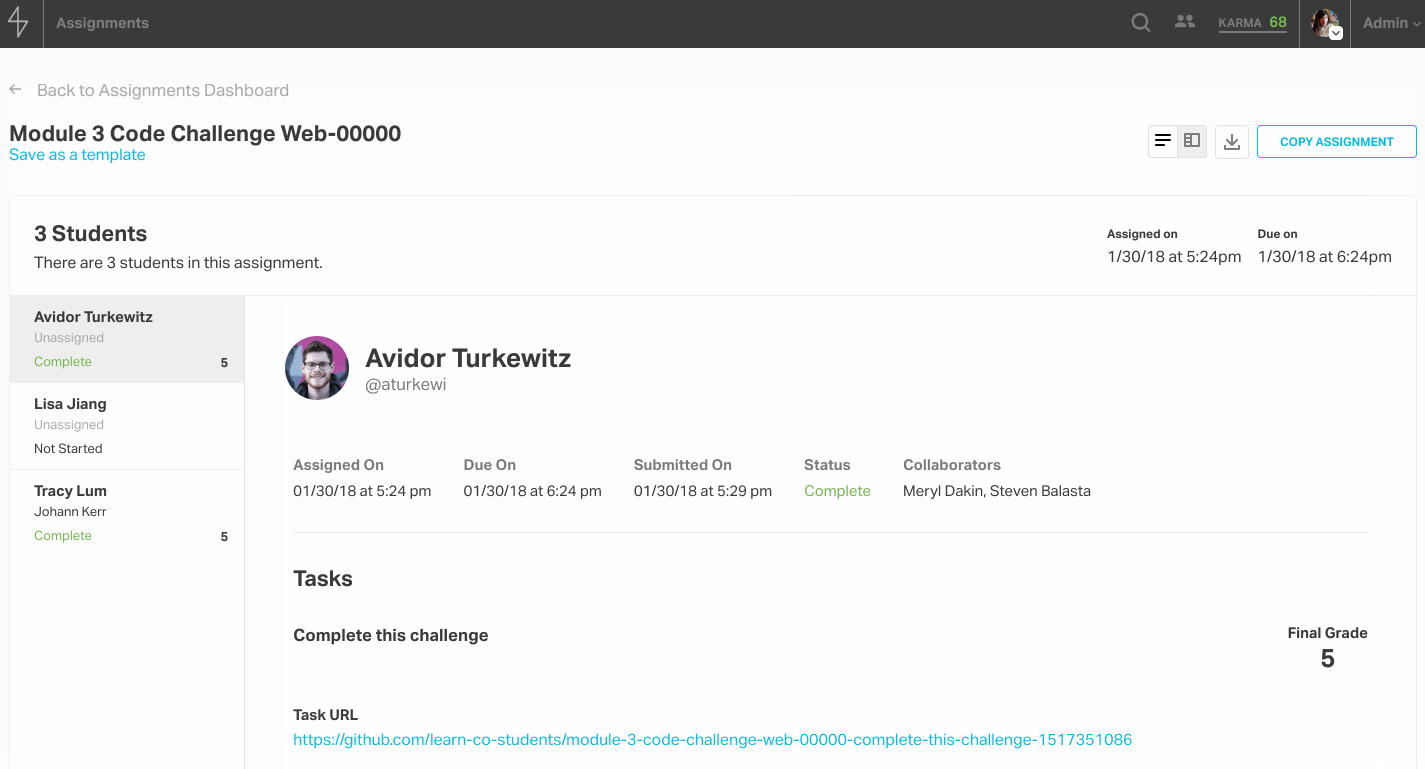
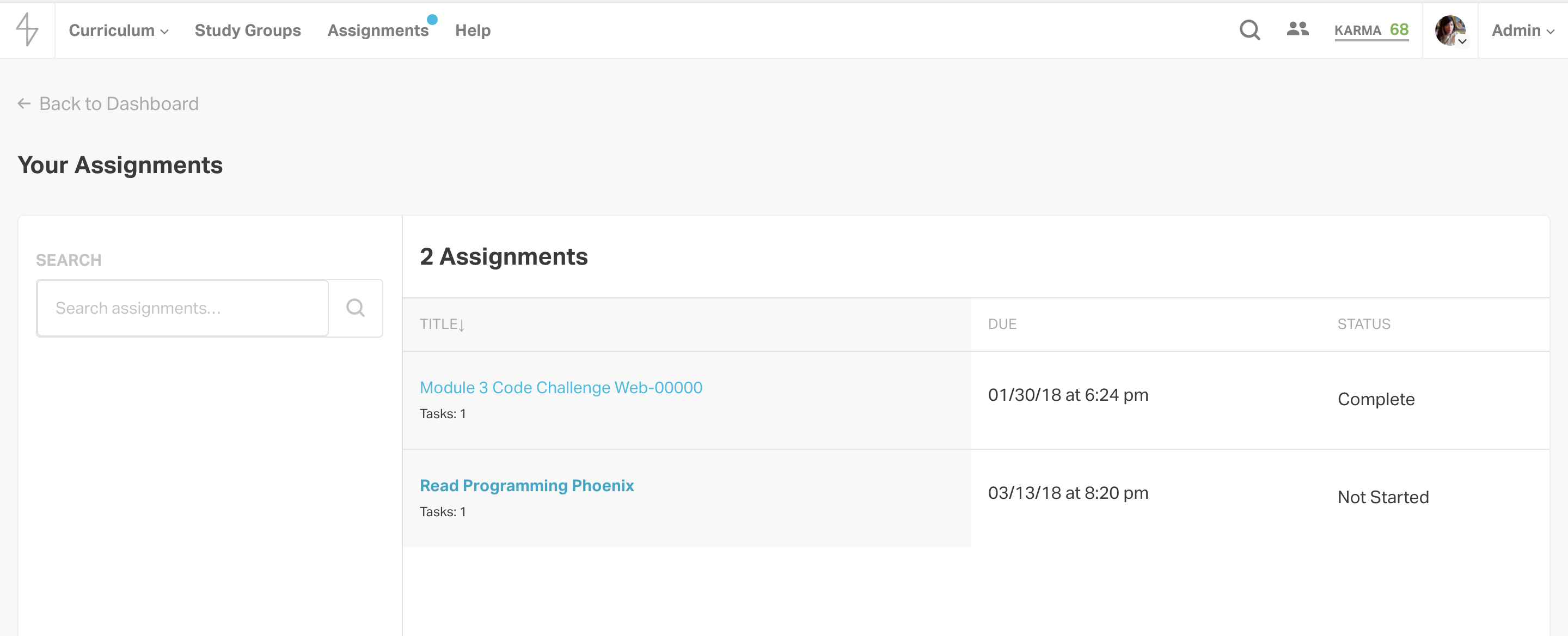
Students who have the assignments feature enabled will see a new item in their site nav called “Assignments.” From there, they can access their assignments dashboard and click into the assignment to see the tasks and a form for completing each one. At the moment, this feature is available to in-person immersive batches.
Engineering Challenges
For a feature that sounds simple because it consists of to-dos, one of the first kinds of apps most budding developers learn to build, this feature became quite complex for a number of reasons.
More Granular Permissions for GitHub Deploys
First, although we designed the backend for the feature using domain-driven design and copious amounts of namespacing, legacy code and ways of solving the problem of deploying curriculum to students weighed in our minds. Much of Learn.co is built for handling actions for groups or cohorts of students. Dealing with batches of students with the GitHub API has historically been simpler because each cohort has been able to act together as a GitHub team for permissioning purposes.
In the new world of assignments, we sought to provide admins the granularity to grant individual students access to a repo. Doing so makes it easier to handle one-off assignments, or even retakes of code challenges. Rather than trying to reuse the existing deployment services in our codebase, we ended up writing new class called CodeChallengeDeployingUser that provides a User object with additional functionality in a specific context and is put to use in a service called DeployCodeChallenge. These two objects work closely together to execute a procedure and surface errors.
Here’s a code sample of how the deployment of challenge works:
class DeployCodeChallenge
attr_reader :git_source_url, :deployable_task, :deployer, :assignees, :errors
attr_accessor :deployed_repo_url
def initialize(git_source_url:, deployable_task:, deployer:, assignees:)
@git_source_url = git_source_url
@deployable_task = deployable_task
@deployer = to_deploying_user(deployer)
@assignees = to_github_collaborators(assignees)
@errors = []
end
def execute
Dir.mktmpdir do |working_dir|
deployer.clone(git_source_url, deployable_task, working_dir)
deployer.create_remote_repo(deployable_task)
deployer.push(deployable_task, working_dir)
self.deployed_repo_url = deployer.destination_repo_url(deployable_task.challenge_name)
deployer.add_assignees_as_collaborators(deployable_task, assignees)
deployer.accept_invitations(deployable_task, assignees)
end
end
private
def to_deploying_user(user)
CodeChallengeDeployingUser.new_from_user(user, self)
end
def to_github_collaborators(assignees)
assignees.map{|a| to_github_collaborator(a)}
end
def to_github_collaborator(assignee)
GithubCollaborator.new_from_user(assignee)
end
endOne of the neatest parts of this code snippet lies in how, within this service object, the User can play either the role of a CodeChallengeDeployingUser or a GithubCollaborator. In the initialize method, we accept a deployer, which is a User object, as well as an array of assignees, that are also essentially User objects.
Neither class inherits from User, but each has a set of different behaviors and attributes, which draws from the decorator pattern. Personally, I also love how the steps in the execute method clearly describe and also echo the manual procedure the instructional staff follows, which makes it easier to read and debug in the future.
Nested Trees of Data
Another challenge we faced was dealing with a large tree of nested data due to how intricately linked our models were. In looking back at the features we’ve built over the past few years, the assignments editor very well may have been the most complex form we’ve built to date. In brief, the domain model we’re primarily dealing with is as follows:
- Assignments belong to a creator.
- Assignments have many tasks. Tasks belong to an assignment.
- Assignment have many collaborators as users, through collaborations.
- Tasks can have many rubric items.
- Assignments have many assignees as users, through assigned works.
Complicating this domain is the fact that we can create most of these things from a single form. An admin can toggle between the three tabs and update the information on any of the models before initiating a write to the database.
To create application harmony between the frontend (React-Redux) and backend (Rails), we decided to send down a tree of JSON data to seed a Redux store and then handle updates in any of the three tabs of the assignment form in Redux state first. That is, whenever we modify a field in the form, we dispatch a Redux action and update state in Redux. When an admin saves the assignment, the entire tree of data is sent to the backend, parsed, and persisted.
Let’s trace the lifecycle of an update. To begin, here’s an example of the structure of the assignment stored in Redux state that is returned when the component fetches some data from an endpoint on the Rails API:
{
assignment: {
id: 1,
title: 'Read Programming Phoenix',
description: 'Learn about Elixir and create a Phoenix app in the process!',
started_at: null,
due_at: null,
creator_id: 1,
created_at: '2018-02-13T20:32:29.178-05:00',
updated_at: '2018-02-13T20:32:29.178-05:00',
due_in: null,
due_in_units: null,
published: false,
tasks: [],
assignee_ids: [],
collaborator_ids: []
}
}If you were to update an attribute on the assignment itself, such as the title or due_in, we dispatch a Redux action from the component when the value of an input field changes. For simplicity, imagine a component that renders an input field with an onChange handler.
// defined in actions.js
export const modifyActiveAssignment = (attribute, value) => ({
type: MODIFY_ACTIVE_ASSIGNMENT,
payload: {
attribute,
value
}
})
// defined in the React component
// code omitted
render() {
return(
<li>
<input
id='title'
name='title'
className='input'
type='text'
onChange={(e) => this.props.modifyActiveAssignment(‘title’, e.target.value)}
value={this.props.assignment.title}
ref={ref => this.titleInput = ref}
/>
</li>
)
}This action will be handled in our editorReducer, which will update the appropriate attribute in our Redux state. The same is true for any form input in the assignments editor. For tasks, we actually delegate much of the work to a separate tasksReducer that is called within the editorReducer to make it easier to update nested state:
// editorReducer.js
case MODIFY_ACTIVE_ASSIGNMENT:
const { attribute, value } = payload
return { ...state, active: { ...active, [attribute]: value } }
case ADD_TASK:
case SHOW_TASK:
case UPDATE_TASK:
case REMOVE_TASK:
const tasks = tasksReducer(active.tasks, action)
return { ...state, active: { ...active, tasks } }Finally, when a user saves the assignment, we send the entire assignment tree stored in the Redux state to a Rails API endpoint that handles updating assignments.
After we sanitize the parameters in the controller and call out to several domain methods, we eventually get to the crux of the update:
# This code lives in a module that we use to namespace our application as part of domain-driven design. You might call this an aggregate root.
def self.update_assignment(assignment_id, title:, description:, collaborator_ids:, assignee_ids:, tasks:, due_in:, due_in_units:)
assignment = Assignment
.includes(tasks: :rubric_items)
.find(assignment_id)
assignment.update(
title: title,
description: description,
due_in: due_in,
due_in_units: due_in_units
)
assignment.set_tasks_from_list(tasks)
assignment.set_collaborators_from_list(collaborator_ids)
assignment.assign(assignee_ids)
assignment.save
PublishableAssignmentValidation.new(assignment).validate
AssignmentManagementView.render_assignment_details(assignment)
end
As you can see, first we handle updating attributes of the assignment model. Then, we call out to assignment model methods that handle updating the related models and their attributes, leveraging the power of Rails mass assignment throughout. In fact, every time the assignment is saved, we destroy the existing associated tasks and rubric items, and re-create them from the payload.
# assignment.rb
def set_tasks_from_list(task_attributes)
self.tasks = self.tasks.new(task_attributes)
end
def set_collaborators_from_list(collaborator_ids)
collaborators = collaborator_ids.map { |id| { collaborator_id: id } }
self.collaborations = self.collaborations.new(collaborators)
end
def assign(assignee_ids)
assignees = assignee_ids.map { |id| { assignee_id: id } }
self.assigned_works = self.assigned_works.new(assignees)
endAfter we persist the assignment, we also run it through the validator because it’s not a terribly expensive operation and because it allows us to simplify the logic of updating an assignment from various places in our app.
You’ll also notice that we need to return JSON from the API, but that we don’t actually use ActiveModel::Serializer. Instead, because these complex, data-heavy views each required a different set of data, we played with the idea of calling “render” functions, which were influenced by the idea of render functions in the Phoenix framework. As our team debates the practicality of moving toward a GraphQL instead of RESTful API, these render functions helped us cut down on querying for extraneous data that model serializers tacitly condone.
Delayed Validations
Related to the complexities of creating assignments is the way in which we validate assignment attributes. Because we allow users to save works in progress, we decided it made more sense to validate the assignment and surface errors in a modal when the user tries to publish rather than save the assignment. We ended up writing a PublishableAssignmentValidation class whose primary responsibility is to ensure that an assignment satisfies all the requirements for publication. These are no longer model-level validations, but workflow validations.
class PublishableAssignmentValidation
attr_reader :assignment
def initialize(assignment)
@assignment = assignment
end
def valid?
validate
assignment.errors.none?
end
def validate
AssignmentNotPublishedValidator.new.validate(assignment)
HasAtLeastOneTaskValidator.new.validate(assignment)
HasAtLeastOneAssigneeValidator.new.validate(assignment)
GradedTasksHaveRubricValidator.new.validate(assignment)
RubricItemsHaveRequiredAttributesValidator.new.validate(assignment)
end
end
class HasAtLeastOneTaskValidator
def validate(record)
record.errors.add(:assignment, "must have at least 1 task") if record.tasks.empty?
end
end
In the snippet above, the PublishableAssignmentValidation calls out to smaller objects that all respond to the same interface of validate to determine whether something is valid for publication. If a rule is not satisfied, the class will collect the errors. The errors will be sent to the front end, which lists all the errors in a modal. Only when all the errors have been corrected does a publishing confirmation modal appear.
Lessons Learned and Impact
Assignments was one of the largest features we’ve rolled out in recent months, and despite the challenges of keeping a multi-person, multi-month, incredibly complex project with dozens of stories organized, we were able to write some really clean and functional code that also made an enormous impact. From implementing domain-driven design and upgrading to React 16 and React Router 4, to trying out some Phoenix-flavored patterns in our APIs, we got to have a lot of fun with a project we cared deeply about, especially since many of us are ourselves former Flatiron School students and teachers.
Even better, after the assignments feature was rolled out to all of the in-person cohorts, we surveyed instructors and found that the average time to grade a challenge dropped by roughly 50% to a mere 3 hours per instructor on average! Over time, as we introduce additional features, such as a template library, we expect that time spent creating and grading challenges to decline even further.
A feature like this is possible only through intense collaboration among the education, product, design, and engineering teams. In future iterations, we’re excited to incorporate user feedback and figure out new ways to streamline and enhance the learning experience for students and staff alike.