Living with Legacy JavaScript: Event Proxies, App Seams, and the Road to Rewrites

Last week, I had the privilege of speaking at this year's EmpireJS conference! The following is the text of my talk, or really, everything I intended to say. This was my first conference talk ever, so that was both exciting and terrifying. I'm glad I did it, but even happier to be done with it.
Anyway, enjoy!
Living with Legacy JavaScript
Every day, I get to work on a magical platform called Learn.co that helps us at the Flatiron School teach people how to code. Learn does a lot. It’s mostly a learning management system, but it also has a bunch of extra features baked into it. In addition to our lesson pages, we have a career services portal, study groups, blogging, and an in-browser IDE to name a few. But while Learn is amazing and I love it and love working on it, it’s also a few years old. Which brings us to legacy code.
Legacy Code
Old doesn’t even necessarily make a codebase bad. Old doesn’t necessarily make a codebase legacy, however. So before we get started, let’s talk definitions. Here are some of the definitions of legacy code over on StackOverflow and elsewhere on the internet:
- "By using hardware, software, APIs, languages, technologies or features that are either no longer supported or have been superceded, typically combined with little to no possibility of ever replacing that code, instead using it til it or the system dies." StackOverflow
- "Legacy code is code that we’ve gotten from someone else." Excerpt From: Michael C. Feathers. “Working Effectively with Legacy Code.” iBooks.
- "To me, legacy code is simply code without tests." Excerpt From: Michael C. Feathers. “Working Effectively with Legacy Code.” iBooks.
Now that we’ve checked our terms, I am pretty confident that the code I’m working with on a daily basis meets at least most of the requirements. Does it include technologies that are no longer supported? Check? Is it from someone else? You bet. Does it have tests? (Sometimes?)
So now we know for sure: legacy codebase. Although it's sometimes hard to work with, it’s kind of exciting to figure out what a certain module in the app does, or why a function was written the way it was. This is how I get to exercise some of my best detective skills.
Recently, I read Michael C. Feather's Working Effectively with Legacy Code, and one of the chapters encouraged developers to tell the story of code. Without the story, without the context, it’s easy to get into the habit of blaming people for past actions. Nevermind getting angry and frustrated, you might just be confused about what some code is supposed to do. So to avoid that, here goes the story...
When Learn started out in 2014, no one was quite sure how it would turn out. At that point, Learn was intended to be a tool to make delivering curriculum to students easier. It began as a Rails app, with mostly Rails-based views. And when you start with Rails 4 back in 2014, your front-end is primarily spaghetti jQuery.
Since then, our codebase’s front-end has gone through many frameworks and libraries, many of which responded to whatever’s trendy in the JavaScript community. We are products of our times, and the same is true of our code.
In the beginning, there was jQuery. And then there was Ember. Backbone and Marionette entered the scene in May 2015. Then Ember left. And then we added React with an Alt.js store. And when Alt.js no longer served our needs, we added Redux. Excluding Ember, all of those libraries still exist in our codebase, and making them work together is often difficult and frustrating.
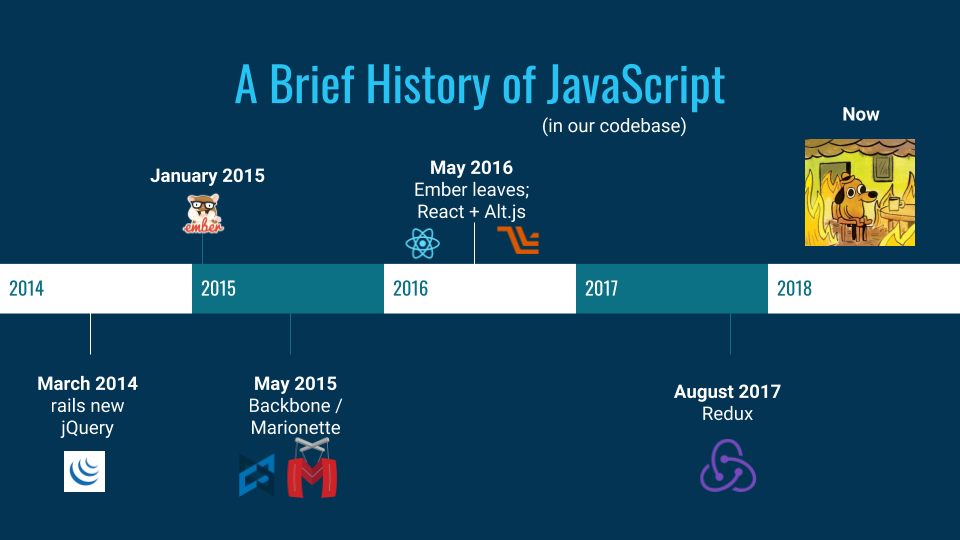
When I’m working with all these libraries, the temptation to burn it all to the ground and start from scratch is pretty strong. I take one look at the abundance of files, some of them seemingly nonsensical, and want to flip a table. I like pristine, new and shiny code, not this crufty stuff.
But then I remember that this is the reality of working with a codebase that’s been around for more than a couple years and has been touched by dozens of people. At the time, it served its purpose. A lot of it was written quickly and without tests, but the code did do its job at the time. So the challenge for the team and me now is to work with it and extend it. After all, this code is our house, and we should do our part to make it better.
So, today, I’ll be talking about a few practical examples of strategies that we’ve used on the Flatiron School engineering team to make it easier to work with a multiplicity of frameworks in a legacy codebase. Most of which were informed by a new feature requirement. Some of them have made my job significantly easier, but there were a couple stumbling blocks along the way. I’ll focus more on finding ways to move forward rather than paying down technical debt, but at some point, which we’ll build to, you’ll probably need to determine if a rewrite is more efficient than a patch.
Build a bridge: IN-BROWSER IDE AND THE RADIO-REDUX PROXY
So, this is a typical lesson page on Learn. Most of what you’re seeing here is managed by Backbone and Marionette.

This past year, we decided to build an in-browser IDE. I know, ambitious and also super dope. That is difficult enough on its own, but the front-end also presented a couple challenges.
First, we intended to build the UI of the browser IDE in React. Back in 2016, the team decided to write all new apps in React instead of Backbone/Marionette, and this new app certainly met that rule.

The problem is that our entire lesson page is written in Backbone/Marionette and the mocks showed the browser IDE sitting right on top of that lesson. So we had to figure out some way for the two libraries to talk to each other, or do a rewrite.
So this seems like a matter of figuring out just enough of each library to make them work well with each other. Thus began a deeper dive.
Just Enough Backbone/Marionette
As I mentioned earlier, the bulk of the lesson pages on Learn are written in Backbone/Marionette and use Backbone Radio as an event bus.
I’ll be the first to admit that I don’t know Backbone all that well, but the important thing to note here is that there are event emitters and event listeners. Emitters fire off events and the listeners respond to them. That’s basically how the lesson page works.
// app/javascript/deprecated/learn_v2/models/curriculum.js
var Lesson = Curriculum.extend({
show: function show (options) {
this.radio.trigger('show:lesson', this);
}
})
// elsewhere
// listeners respond to event
this.radio.on(‘show:lesson’, lessonCallbacks)Among those events is this.radio.trigger('show:lesson', this); which pretty much everything is listening to. That’s the event that most of the features care about. It pretty much tells the entire world that the lesson is here and that everyone should respond to it as they see fit.
Just Enough Redux
Okay, so now about Redux. Redux, as you probably know, is a state container. The basic idea is that you send actions through reducers in order to change state. Actions consist of a type and a payload, and reducers are just functions that accept actions as arguments and change state based on the type and the payload. Finally, there’s a store that holds application state and registers listeners, so it can notify interested parties whenever app state changes.
So, to make these two disparate systems talk together, we ended up building a bridge to proxy Backbone events to a Redux store.
Sure, we could have gone ahead and rewritten the lesson page in React and Redux...it just would have taken a very long time. We could have argued for the time to unify our frameworks, but building a bridge was the path of least resistance and the solution that we ultimately got buy-in for.
So, the bridge itself is fairly straightforward. We intentionally built it as a one-way street. Only events from Backbone Radio could be forwarded on to Redux. The code for that looks something like this.
// app/javascript/lib/redux/reduxRadioProxy.js
export default (store) => {
const radio = Radio.channel('global')
radio.on('show:lesson', (lesson) => {
const {lessonInfo} = store.getState()
store.dispatch(changeLesson(lesson.attributes))
})
}// app/javascript/lib/redux/store.js
import ReduxRadioProxy from 'lib/redux/reduxRadioProxy'
const store = createStore(reducers, defaultState)
ReduxRadioProxy(store)
export default storeWe tune into the global Radio channel and just start listening for events. When we get that event, we begin dispatching the Redux actions we care about, the ones that need to do something in response to the lesson changing.
With this bridge in place, we could do things like close the browser or dismiss flash messages, and we’d leave everything that lives in Backbone/Marionette in place. This was the easiest way to keep moving forward, and we built the in-browser React components pretty quickly with this proxy in place. We also established a flexible way to proxy messages in case other apps need them. Since then, our proxy has in fact grown. But still, we knew that eventually we wanted to rewrite all the Backbone apps in React one day.
Look for the seam: TRACK NAV, JUPYTER NOTEBOOKS, AND THE SEAM HUNT
Whenever we have the opportunity, we try to find ways to port over Backbone/Marionette apps to React. But the trickiest part of doing this is finding the seam.
TRACK NAV
The first successful case I want to talk about is our Track Nav. The strategy that the Track Nav migration used was to maintain Backbone models and replace the Backbone view with a React one. This way, anything that was listening to the track model’s lifecycle events remains intact, and our views are rendered by React. This means that the seam was just in the view.
// app/javascript/deprecated/learn_v2/apps/track_nav/track_nav_view.js
import CurriculumContainer from './containers/CurriculumContainer.jsx';
var TrackNavView = Backbone.View.extend({
render: function render() {
this.reactComponent = React.createElement(
CurriculumContainer,
{ this.model, view: this }
)
ReactDOM.render(this.reactComponent, this.el);
}
});This works. It’s great, but it isn’t quite the full replacement that we wanted. There’s a nice seam between Backbone and React, but it isn’t the pattern that will enable us to eradicate Backbone from the system.
JUPYTER NOTEBOOKS
A few months ago, the business wanted to integrate Jupyter Notebooks into our platform. In addition to all the backend work to spin that up, which, again, warrants its own talk, we had to make a blue button unclickable while some actions ran on a remote server. The way we spin up Jupyter Notebooks for students leverages the same backend as the IDE, so again, communications happen over Phoenix sockets, and messages are being piped into our reducers as actions.

Once again, the lesson page is nearly all in a tightly coupled Backbone/Marionette app. My first impulse when I saw this requirement was to cheat. Couldn’t we use a timeout to re-enable to button click? Wasn’t there an easier way? There wasn’t. If something in this chain of events went awry somewhere, it would just be too weird of a user experience to recover from.

And so, my next question was can we rewrite this part of the app in React / Redux? This super cool button lives inside an app called the ToolbarApp. It’s super tiny. It only manages a small part of the front-end. It should have been easy enough to wrangle. Our lead dev and I dove into the code and started hunting for the seam. We wanted to provide a path forward for all new apps to be rewritten, and to do this, we were looking for a nice pinch point where we could neatly form a barrier between React and Backbone.
// app/javascript/deprecated/learn_v2/apps/toolbar/index.js
var ToolbarApp = BaseApplication.extend({
shouldStart: function () {
return this.hasRegion('subheader');
},
radioEvents: {
'show:lesson': 'onShowLesson'
},
onShowLesson: function onShowLesson (lesson) {
this.subheaderRegion().show(this.toolbarView(lesson));
},
…
toolbarView: function toolbarView (lesson) {
return new ToolbarView({model: lesson});
}
});// app/javascript/deprecated/learn_v2/apps/toolbar/toolbar_view.js
events: {
'click @ui.editorToggle': 'onEditorToggleClick',
'click @ui.fullscreenToggle': 'onFullScreenToggleClick',
'click @ui.openIdeInBrowserButton': 'onOpenIdeInBrowserClick',
'click @ui.jupyterRunButton': 'onJupyterRunButtonClick'
},
initialize: function initialize
BaseItemView.prototype.initialize.apply(this, arguments)
this.fullScreenMode = document.fullScreen || document.mozFullScreen || document.webkitIsFullScreen
$(document).on('mozfullscreenchange webkitfullscreenchange fullscreenchange', this.onFullScreenChange)
},
We timeboxed our exploration and did a rough estimate of how hard it would be. There were just too many dependencies, especially with the way that the layout was written. Ultimately, we couldn’t justify rewriting that chunk just then. Then we moved on to building a reverse bridge. Not ideal, but this product had to ship by a certain date, and once again, the bridge made it easier.
The reverse bridge we really unimaginatively titled the radioReduxProxy to indicate that it goes the other way. This flow is a little more complicated.
// app/javascript/lib/redux/middleware/radioReduxProxy.js
// Proxies events from redux to radio
export default (store) => next => action => {
switch (action.type) {
case JUPYTER_RUN_TESTS_DONE:
radio.trigger('run:jupyterNotebookTests:done')
break
case JUPYTER_READY:
radio.trigger('jupyterNotebook:ready')
default:
break
}
next(action)
}The backend knows when the tests are done running. It sends a message over the websocket to our Jupyter Notebook channel in the client. The client responds by dispatching a Redux action. We’ve built our radioReduxProxy into our middleware so that it intercepts the message. Middleware is a great place for code with side effects. You should keep your reducers pure, so we put our code in the middleware because that’s where the weird stuff goes. And this is certainly weird stuff. So, the middleware triggers a radio event, and the listeners on the view respond to that event by re-enabling the button. What a flow!
We completed the button and now data science is program on Learn! We ended up building a reverse bridge, but again, we ultimately knew that we would have to rebuild or rewrite soon.
Rebuild when the time is right: THE DUAL EXISTENCE OF LESSON PAGE AND THE BUGS
So at this point, we’re still dealing with a pretty grotesque amalgam of code. There are different frameworks and libraries for different sections of the app, and we’ve pretty much built a lot of bridges.
And that was mostly fine. The app works. It’s definitely got some bloat, but what app doesn’t?
But then finally, the day came for a partial rewrite! We’ve been itching to do this for ages! The business requirement was to implement a stripped down version of the lesson view for certain users. Because this requirement touched the entire lesson app and not just a small section of it, this seemed like the best opportunity we were going to get to rewrite the Backbone/Marionette app in React. The seam, we realized, wasn’t at the toolbar level, but one level up: at the lesson page itself. And so set out to rewrite, based on this seam!
Which was actually a little harder than expected. As it turns out, there’s a lot of code that goes into displaying that lesson page. We have all sorts of lesson types and assessments for each type of lesson, which we call “lights.” Lights are a beloved part of the app. Students go wild over them, especially when they don’t work.
We went from sprawling code that looked like this…
├── index.js
├── templates
│ ├── assessment.pug
│ ├── assessments
│ │ ├── blog_post_url.pug
│ │ ├── choose_team.pug
│ │ ├── fork.pug
│ │ ├── github_url.pug
│ │ ├── learn_hello.pug
│ │ ├── live_review_signoff.pug
│ │ ├── local_build.pug
│ │ ├── pull_request.pug
│ │ ├── quiz.pug
│ │ ├── remote_build.pug
│ │ ├── self_review.pug
│ │ ├── signature.pug
│ │ └── walkthrough_url.pug
│ ├── assessments.pug
│ ├── mixins
│ │ ├── helpfulness.pug
│ │ ├── streak.pug
│ │ ├── total_lessons.pug
│ │ └── velocity.pug
│ ├── override_modal.pug
│ ├── reset_modal.pug
│ ├── review_criterion.pug
│ ├── search.pug
│ ├── search_empty.pug
│ ├── search_suggestion.pug
│ ├── selected_search_result.pug
│ ├── share_confirm.pug
│ ├── share_form.pug
│ ├── share_success_modal.pug
│ └── teammate.pug
└── views
├── assessments
│ ├── base.js
│ ├── blog_post_url.js
│ ├── choose_team.js
│ ├── fork.js
│ ├── github_url.js
│ ├── learn_hello.js
│ ├── live_review_signoff.js
│ ├── local_build.js
│ ├── pull_request.js
│ ├── quiz.js
│ ├── remote_build.js
│ ├── self_review.js
│ ├── signature.js
│ └── walkthrough_url.js
├── assessments.js
├── override_modal.js
├── quiz_question.js
├── reset_modal.js
├── review_criterion.js
├── share_form.js
├── share_success_modal.js
├── teammate.js
└── teammate_search.js
To code that looked like this...!
├── LessonContentContainer.jsx
├── LightsContainer.jsx
└── components
├── LessonContent
│ ├── OpenButton.jsx
│ ├── Readme.jsx
│ └── Toolbar.jsx
└── Lights
├── BaseLight.jsx
├── ForkLight.jsx
├── LightFooter.jsx
├── LocalBuildLight.jsx
└── PullRequestLight.jsx
// app/javascript/lib/lesson/LightsContainer.jsx
const LightsContainer = ({ assessments, solution_branch_url }) => {
return (
<Fragment>
{
assessments.map(assessment => (
<LightFactory
key={assessment.id}
assessment={assessment}
solutionBranchUrl={solution_branch_url}
/>
))
}
</Fragment>
)
}
// app/javascript/lib/lesson/LightsContainer.jsx
const LightMap = {
ForkAssessment: ForkLight,
LocalBuildAssessment: LocalBuildLight,
PullRequestAssessment: PullRequestLight
}
const LightFactory = ({ assessment, solutionBranchUrl }) => {
const Component = LightMap[assessment.type]
if (Component) {
return (
<Component {...assessment} solutionBranchUrl={solutionBranchUrl} />
)
}
return null
}We built this code alongside the existing code to make it easier to continue to support the old stuff while we built the new system out.
However, we did run into one large-ish problem along the way because we were maintaining two different systems of rendering a lesson page.
Whenever we loaded the new lesson page, everything seemed to work fine. People could work on their lesson and submit their work, for which they’d then get credit as a light in the right rail. Data would flow through our Redux store and update the right keys in state. It was great.
The only problem was that for some reason, lessons from the old system would sometimes break with this nasty error.
collectionItemHelper.js:104 Uncaught TypeError: Cannot read property 'findIndex' of undefined
at t.getItemIndex (collectionItemHelper.js:104)
at t.getItemById (collectionItemHelper.js:35)
at i (lessonInfoReducer.js:5)
at t.default (lessonInfoReducer.js:24)
at combineReducers.js:120
at u (createStore.js:165)
at jupyterNotebookChannel.js:73
at ideTerminal.js:50
at ideSessionChannel.js:133
at remoteEnvironmentSocket.js:33For a while, we dismissed it, thinking this can’t possibly be right. Maybe it’s just you? But another dev on our team was rightly persistent.
We spent hours debugging, stepping through the controllers, actions, APIs, and finally we figured out that there was just one line of code in the Backbone app that was removing the assessments that we assumed would always be in the Redux store because we were seeding our Redux store with Backbone models.
// app/javascript/deprecated/learn_v2/models/curriculum.js
// Lesson model
assessments: function assessments () {
return this._assessments || (this._assessments = initializeSubCollection.call(this, Assessments, 'assessments'));
},
function initializeSubCollection (constructor, collectionKey) {
…
this.unset(collectionKey) // this is the culprit!
return collection;
}We gitblamed it, and the person responsible for that line also happened to be the person I was pairing with at the time, and neither of us could figure out why it was there in the first place. So we went ahead and removed it. Turns out although we were loading the Backbone app on the page, the Redux reducer was still loaded and still trying to update state, even though we weren’t actually trying to read from it.
So, lesson learned. When you rewrite or refactor an app, be sure to come up with a strategy to test. And if you do end up rewriting something, make sure you do it completely. Vestiges of old apps or unimplemented features cause more confusion in the future than they do in the present. As always, the context is key. In the future, I’m sure we’ll get the chance to remove the legacy stuff completely, but for now, they do still exist in the dual state.
Wrap-up and Takeaways
Anyway, those were a lot of stories about the legacy code team and I have had to deal with and some strategies we used to deal with making disparate apps of the codebase communicate and work in harmony. Rewriting your legacy app doesn’t have to be all or nothing. We built proxies to communicate between Redux and radio. We hunted for the right app seams, and we waited for the business requirements to come in before embarking on any sort of rewrite. By waiting until a responsible moment to rewrite, we were able to deliver value, get product buy-in, and also clean up the code in a responsible way. Of course, we encountered a couple bugs along the way, but they were all things that could be avoided with more careful testing, especially of systems that live in parallel. With legacy code, you never know what you’ll find. Sometimes it’s weird, sometimes it’s crazy, but it’s always an adventure.